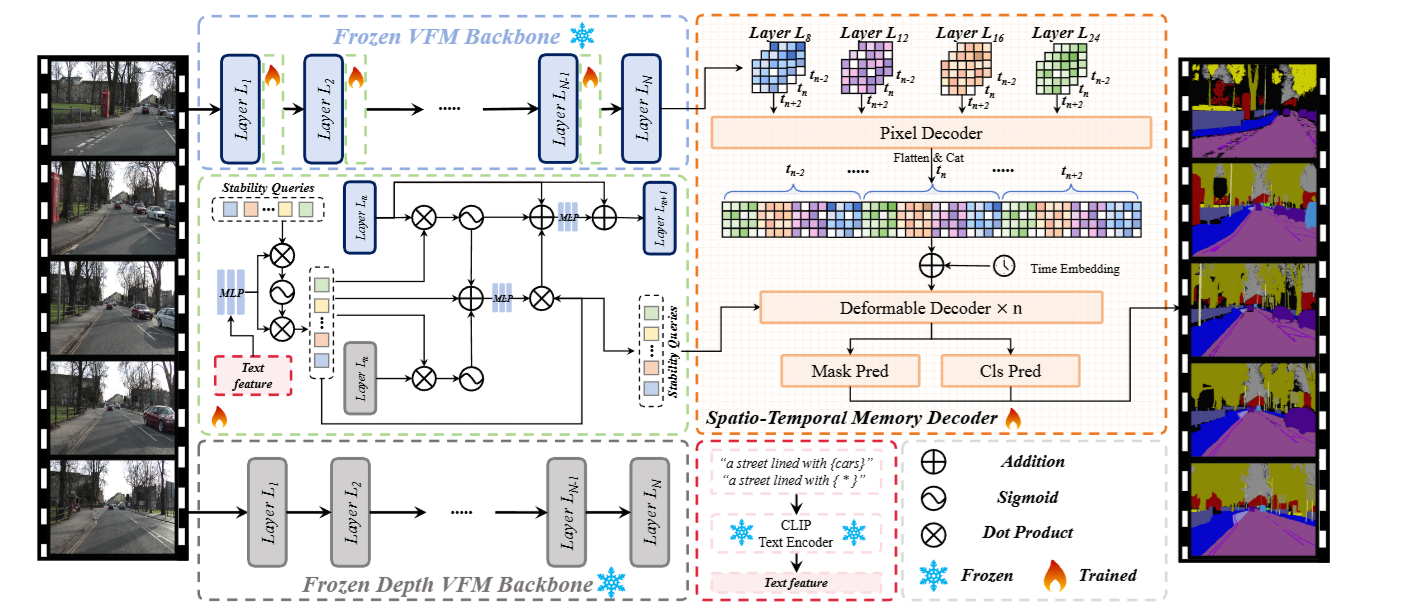
Time2General: Learning Spatiotemporal Invariant Representations for Domain-Generalization Video Semantic Segmentation Published in arXiv, 2026Download Paper